Introducing Project Cosmos: Carbon Brief’s ‘universe’ of climate science
- By Leo Hickman and Ayesha Tandon
- Design and development Kerry Cleaver, Joe Goodman, Tom Pearson and Tom Prater
Carbon Brief’s Project Cosmos is a major collaborative effort to build the world’s largest and most complete database of climate change research.
The Cosmos database – which features more than 1.8m individual publications linked by 40m citation relationships – captures the vast body of human knowledge about climate change that has accumulated over more than a century of academic study.
Cosmos is a major new resource, which has taken more than 18 months to research and build, with help and guidance from a specialist team of academics.
Carbon Brief embarked on Project Cosmos to map and analyse the scientific community’s foundational knowledge about climate change.
This includes, at first, ranking the most highly cited academic publications, authors and institutions.
Together, this series of rankings is known as the Cosmos 500.
But, over time, the database will reveal, for example, how interest in different areas of climate science has changed, plus identify potential knowledge gaps and, thus, opportunities for future research.
- What is climate change research?
- What is the database structure?
- How has Carbon Brief analysed the data?
- Are there other ways of analysing climate literature?
- How did Carbon Brief create the database?
- How can researchers access the database?
What is climate change research?
One of the first scientific studies to connect atmospheric CO2 to a rise in global temperatures was published in 1856 by Eunice Newton Foote.

Other scientific pioneers, such as John Tyndall and Svante Arrhenius, were also drawn to investigate the warming influence of rising atmospheric CO2.
Since then, the scientific community’s understanding about human-caused climate change has increased rapidly, particularly in recent decades. A huge volume of academic studies, books and reports – referred to together here as “publications” – has been published by a wide variety of researchers and institutions around the world.
The bulk of the publications included in the Cosmos database are academic peer-reviewed studies. The graphic below shows an anatomy of a typical study, including how each includes a list of authors, as well as dozens, sometimes hundreds of references.
Every study has a list of authors. These are the experts who wrote the paper – including carrying out fieldwork, analysing data and drafting the paper itself.
Each publication also includes a list of references – the peer-reviewed studies, books and reports that the authors cite as their supporting evidence.
This list of references is crucial for underpinning the legitimacy of any new research, allowing other academics to trace back important claims to their source and to understand how the new work fits in with the existing body of literature on climate change.
The graphic below shows the “anatomy” of a typical peer-reviewed study.
Project Cosmos aims to map the “universe” of climate science, by uncovering the vast web of references that link millions of publications and authors to one another.
Carbon Brief has used the corpus of reports from the Intergovernmental Panel on Climate Change (IPCC) as the foundation for building a universe of climate science.
The organisation has been publishing the world’s most authoritative summaries of the latest climate science since 1990. To produce a single IPCC report, hundreds of scientists work for years to draw together information from thousands of sources.
The IPCC works in “assessment cycles”, which typically last between five and seven years. There have been six assessment cycles since 1990, with the seventh now underway.
Within each cycle, the IPCC publishes three “working group” (WG) reports on physical science (WG1), impacts and adaptation (WG2) and mitigation (WG3). These are broken down into chapters. The working group reports are then summarised in a “synthesis report”.
A shorter “summary for policymakers” is also published for each working group report, which is approved line-by-line by member governments.
In addition, the IPCC has published 14 “special reports” since 1990 focusing on specific areas of climate change, which are each commissioned and produced within an assessment cycle. It has also published a series of “methodology reports”.






For the first time ever, Carbon Brief has set out to extract the references from every major IPCC report ever published.
The analysis includes all working group reports and special reports. However, it does not include the synthesis reports, as these reports are summaries of the main working group reports and repeat the same references. It also does not include the more niche and technical IPCC methodology reports.
In total, the IPCC working group reports and special reports contain more than 100,000 references. The chart below shows how many references are listed in each IPCC assessment report and their working groups.
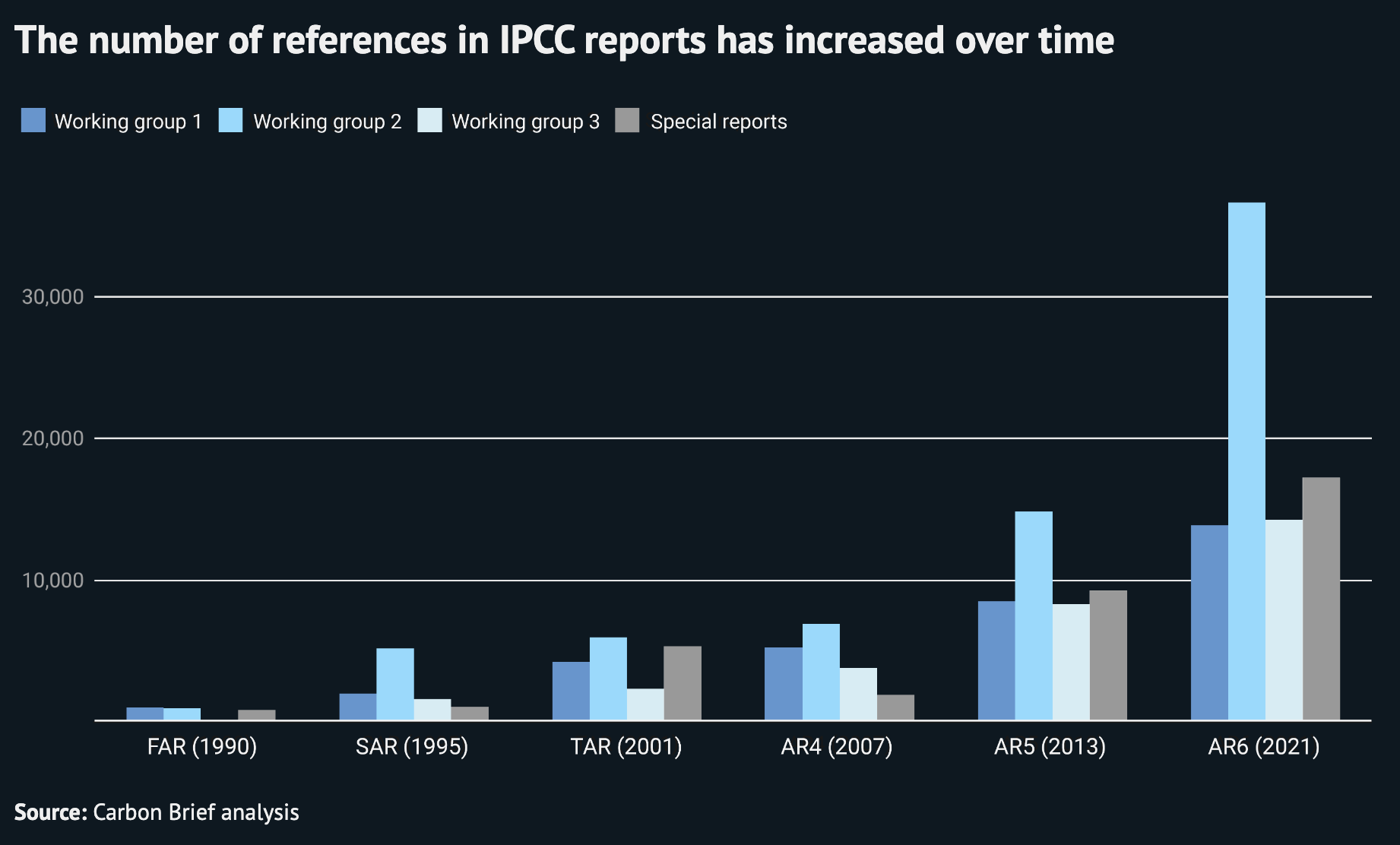
The number of references in IPCC reports has increased almost 40-fold over the past three decades. The first assessment cycle lists 2,315 references in total, whereas the sixth cycle lists 82,523.
What is the database structure?
References from IPCC reports make up the foundation of Carbon Brief’s “cosmos” of climate science.
Since its first report was published in 1990, the IPCC corpus has referenced 107,000 unique studies, reports and books. These publications form the “IPCC-only” section of the Cosmos database.
Carbon Brief has then expanded on this core to build-out the full Cosmos database, as described in the graphic below.
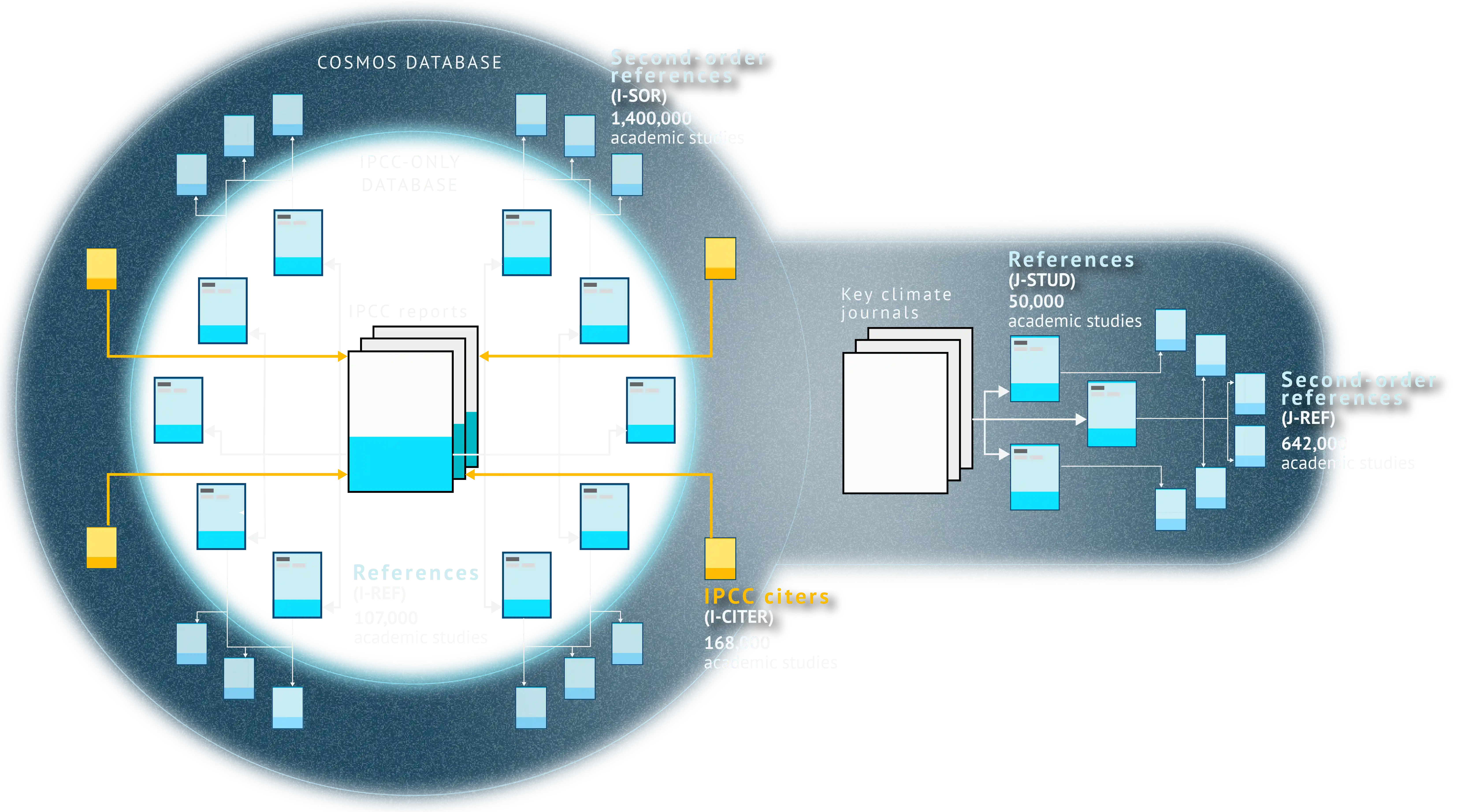
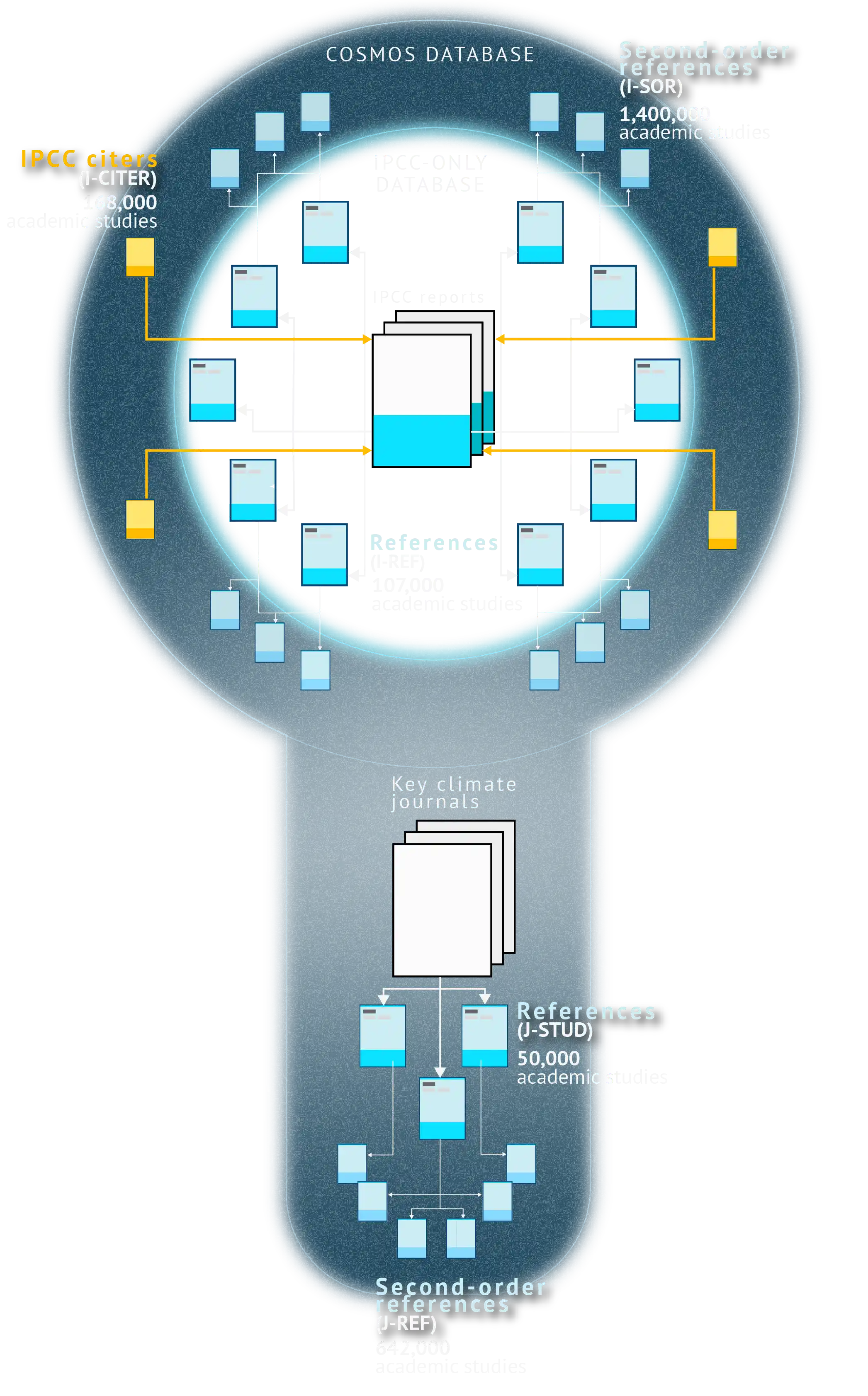
Carbon Brief began by extracting and analysing every study referenced by the IPCC reports, to identify each of the studies that they reference. This process resulted in 1.4m second-order references.
Next, Carbon Brief identified every academic study that lists at least one IPCC report or chapter in its own references. There are 168,000 of these publications, which are referred to as “IPCC citers” (see below).
Not every paper focuses on climate change specifically. However, they are all linked to IPCC reports by either one of two citation steps, giving them all some degree of influence on the current state of human knowledge on climate change.
Carbon Brief also identified – with input from its 2024-26 cohort of contributing editors – 22 peer-reviewed academic journals that only publish articles about human-caused climate change.
Carbon Brief extracted all the studies from these climate-focused journals published up to 31 December 2025, to make sure that all influential studies about climate change are captured in the Cosmos database – even if they have not been directly referenced in other IPCC-linked literature.
The table below lists the 22 journals, the years they launched and the number of studies they have each published in total.
| Journal | Launch year | Number of studies |
|---|---|---|
| Advances in Climate Change Research | 2010 | 1,033 |
| Climate and Development | 2009 | 1,055 |
| Climate Change Economics | 2010 | 414 |
| Climate Policy | 2000 | 1,963 |
| Climate Risk Management | 2012 | 768 |
| Climate Services | 2015 | 573 |
| Climatic Change | 1977 | 6,933 |
| Current Climate Change Reports | 2014 | 201 |
| Dialogues on Climate Change | 2024 | 20 |
| Energy and Climate Change | 2020 | 275 |
| Environmental Research: Climate | 2023 | 245 |
| Frontiers in Climate | 2019 | 1,035 |
| Global and Planetary Change | 1989 | 4,810 |
| International Journal of Climate Change Strategies and Management | 2009 | 891 |
| International Journal of Climatology | 1981 | 8,610 |
| Journal of Climate | 1988 | 13,598 |
| Nature Climate Change | 2011 | 5,265 |
| npj Climate Action | 2022 | 286 |
| PLOS Climate | 2022 | 587 |
| Weather and Climate Extremes | 2013 | 806 |
| Weather, Climate and Society | 2009 | 869 |
| Wiley Interdisciplinary Reviews Climate Change | 2010 | 882 |
Carbon Brief did not include high-impact multidisciplinary journals such as Nature and Science, which publish articles on a wide range of topics, given that the majority of climate-focused studies they might have published will likely have been cited by at least one of the other sources listed above.
In total, more than 50,000 academic studies have been published by these 22 peer-reviewed journals.
Finally, Carbon Brief identified the references within each of these studies, resulting in a further 642,000 unique publications.
Overall, the Cosmos database contains five distinct pillars of data:
- I-REF: The studies, books and reports referenced across all IPCC reports since 1990. (Total: 162,552. Unique: 106,782.)
- I-SOR: The studies, books and reports referenced in the I-REF data. These are “second-order references”. (Total: 7,482,440. Unique: 1,383,877.)
- I-CITER: The studies that themselves reference IPCC reports or chapters, known as “IPCC citers”. (Total: 221,162. Unique: 167,740.)
- J-STUD: The studies published in 22 climate-focused journals. (Total: 51,804.)
- J-REF: The studies, books and reports referenced in the J-STUD data. (Total: 2,205,012. Unique: 641,917.)
The database contains 1,816,639 unique publications, but, including duplicates, the total number of citation “relationships” stands at just over 40m. More than 1.3m of these unique publications are classified in the database as peer-reviewed “studies”, while the others are predominantly books and reports (including what is sometimes referred to as “grey literature”).
More than 97% of these publications are in English. However, there are also publications in other languages – most notably French and Spanish.
The oldest publication in the Cosmos database was published in 1483 under the title: “Theophrasti De Historia plantarum liber primus[-decimus].”
It was the first Latin translation published in print of Theophrastus’s “Historia Plantarum” (Enquiry into Plants), which is considered to be one of the “most important books of natural history written in ancient times”.
![Theophrasti De Historia plantarum liber primus[-decimus] ragout](../images/oldest-paper-ragout.webp)
How has Carbon Brief analysed the data?
Project Cosmos is a first-of-its-kind resource, which opens the door for a vast array of future research.
One initial key line of analysis involves using the database to identify cornerstones of climate literature, as well as the leading hubs and authors of influential research.
Carbon Brief has used the database to produce three rankings, collectively known as this “Cosmos 500”. These are the 500 most influential publications, authors and institutions in the database.
Publications that are referenced extensively by other academic papers, books and reports are often referred to in academia as being “highly cited”.
To produce these rankings, Carbon Brief defined a metric called the citation score. This is the number of times that each academic paper, book and report is referenced by the others in the database.
Carbon Brief identified and omitted the IPCC reports and chapters from the final ranking of citation count. This is because their citation count would be substantially higher than that over other publications and would have an outsize influence on the rankings. A key aim of Project Cosmos was to identify and analyse the foundational science that underpins climate knowledge, not the extent to which IPCC reports cite other IPCC reports.
This means that IPCC reports and chapters are not included when calculating citation scores for authors. They are also not included in the Cosmos 500 ranking of the most highly cited publications in the Cosmos database.
A publication’s citation count only shows how highly cited it is within the Cosmos database. It does not indicate how highly cited the study is in broader academic literature.
Carbon Brief has ranked the database’s most highly cited authors – the experts who wrote each academic paper, book and report.
In total, there are more than 1.6m unique experts listed in the entire Cosmos database.
Carbon Brief has added up the citation counts for the publications written by each expert. This provides a metric showing how highly cited each expert’s publications are within the database.
(To allow comparison with their wider academic impact, Carbon Brief has included within the Cosmos 500 rankings each author’s h-index, according to Google Scholar. This is a metric that calculates the productivity and citation impact of an author’s publications. It is calculated for all publications that each expert has written – not just those included in the Cosmos database.)
Again, Carbon Brief has not included citation counts for IPCC reports and chapters, which have a much higher citation count within the database than all other types of literature.
Finally, Carbon Brief has ranked the most highly cited institutions in the database.
Often, a parent institution is linked to a group of subsidiary organisations. For example, the University of London encompasses a range of institutions including University College London, King’s College London and the London School of Economics. In this case, only the subsidiary organisations are counted.
Carbon Brief has also used OpenAlex (see below for explanation) to identify which institution – such as, a university, laboratory or research institution – each author was affiliated with when their paper was published. Carbon Brief has linked each publication in the database to the institutions that its authors are affiliated with at the time of publication.
To get the final ranking, Carbon Brief has added the citation counts for publications linked to each institution.
Separately, Carbon Brief has also carried out the same analysis using the “IPCC-only” section of the Cosmos database, which only includes the 107,000 “I-REF” studies, reports and books that the IPCC references directly.
Using this database, Carbon Brief ranked the top 500 “IPCC-only” publications, authors and institutions.
This secondary analysis provides an important complement to the main Cosmos 500 rankings, as it shows the publications, authors and institutions that have had the most significant influence within the IPCC reports themselves.
Are there other ways of analysing climate literature?
Bibliometrics is the research field in which experts analyse publications, such as books and articles, to assess the impact of research, identify trends and map hotspots of focus and collaboration.
Researchers have published a variety of bibliometric analyses of climate-science literature to date. These tend to fall into a handful of categories.
One of the main methods is to use keyword analysis. For this method, experts identify a series of words or phrases, then search a bibliographic database, such as Scopus, for papers whose titles, abstracts or keywords include these terms.
Examples of this method have been published in peer-reviewed journals, including Nature Cities and Science Advances.
In 2015, Carbon Brief published an analysis headlined: “The most ‘cited’ climate change papers.” As the article explained: “In Scopus, we searched for any academic paper with the phrase ‘climate change’ or ‘global warming’ in its title, abstract or keywords.”
However, any analysis using keywords – all of which are subjective choices by the researchers – is likely to include both false positives (in which papers are included in the final set which should not be) and false negatives (in which papers which should be included in the final set are excluded).
Scientists have also employed a wide range of other methods to identify literature on climate change, such as the use of machine learning.
Efforts have also been undertaken to identify the most “influential” academics working in climate change.
For example, in 2021, the “Reuters hot list” ranked the 1,000 “most influential” climate scientists, based on data provided by Dimensions – an academic research database.
The ranking considered three factors: the number of papers an individual published; the number of citations the paper received; and the attention the paper received from sources including the news, blogs and social media.
Carbon Brief’s database differs from these past investigations by being, by design, far more expansive and exhaustive in its scope.
First, it uses the entire canon of IPCC literature published since 1990, as well as 22 leading climate-focused journals, as the foundation for all extraction of references.
Second, it then takes a significant, unique extra step by identifying all the second-order references. By deliberately casting the search so widely, the “cosmos” of extracted data has a far higher chance of capturing the vast body of evidence and research that underpins and informs humanity’s understanding of climate change. This can then be filtered down via rankings, etc.
How did Carbon Brief create the database?
Carbon Brief has worked closely with a team of specialist academics to research, construct and maintain the database.
Félix Chavelli, a PhD student in computer science at the National Institute for Research in Digital Science and Technology (Inria) in Paris, led on the data extraction. In 2023, Chavelli co-authored a Carbon Brief guest post, which provided an overview of a study he co-authored that analysed the 13,500 citations within the IPCC AR6 WG1 report.
Additionally, a computational science team from the University of Exeter’s Centre for Climate Change Communications and Data Science (C3DS), led by Dr Tristan Cann with the support of Prof Travis Coan, produced the final database using Neo4j. (See below.)
Carbon Brief first extracted the reference list from each IPCC chapter. Every IPCC report published after 1997 has a digital object identifier (DOI) – an identification number automatically assigned to every study. In addition, IPCC reports are split into chapters, which each have a list of references and their own DOI.
Each chapter of IPCC reports is treated as an individual academic work. This means that if a publication is referenced multiple times within a chapter, Carbon Brief’s database only counts the publication once. However, if multiple chapters in an IPCC report each reference the same publication, Carbon Brief’s database counts these repetitions.
The most recent assessment cycle, AR6, lists their references in an easy-to-process “BibTeX” format. However, some of the older assessment cycles store their references in PDF or plain-text formats, meaning that further data processing was required by Chavelli to extract the references.
Next, the Carbon Brief team used OpenAlex – an open-source catalogue of millions of academic books, papers and reports – to search for each reference by name and date of publication.
(There are many other catalogues of academic works, such as Scopus, Web of Science and Google Scholar. Carbon Brief selected OpenAlex because it is open source and one of the most complete sources of data.)
Carbon Brief also used OpenAlex to obtain up to 30 types of “metadata” about each scholarly work, including key information – such as the name of the paper, DOI number, publication year and a list of the paper’s authors. The metadata also provides an institution – such as a university or government branch – for every author at the time of publication.
In addition, Carbon Brief obtained the OpenAlex ID – a unique identification number that is assigned to every publication.
Carbon Brief also recorded the research topics assigned by OpenAlex to each entry. OpenAlex organises scholarly works into roughly 4,500 topics, arranged in a four-level hierarchy. Every paper, journal or report with enough metadata is assigned to one or more topics automatically.
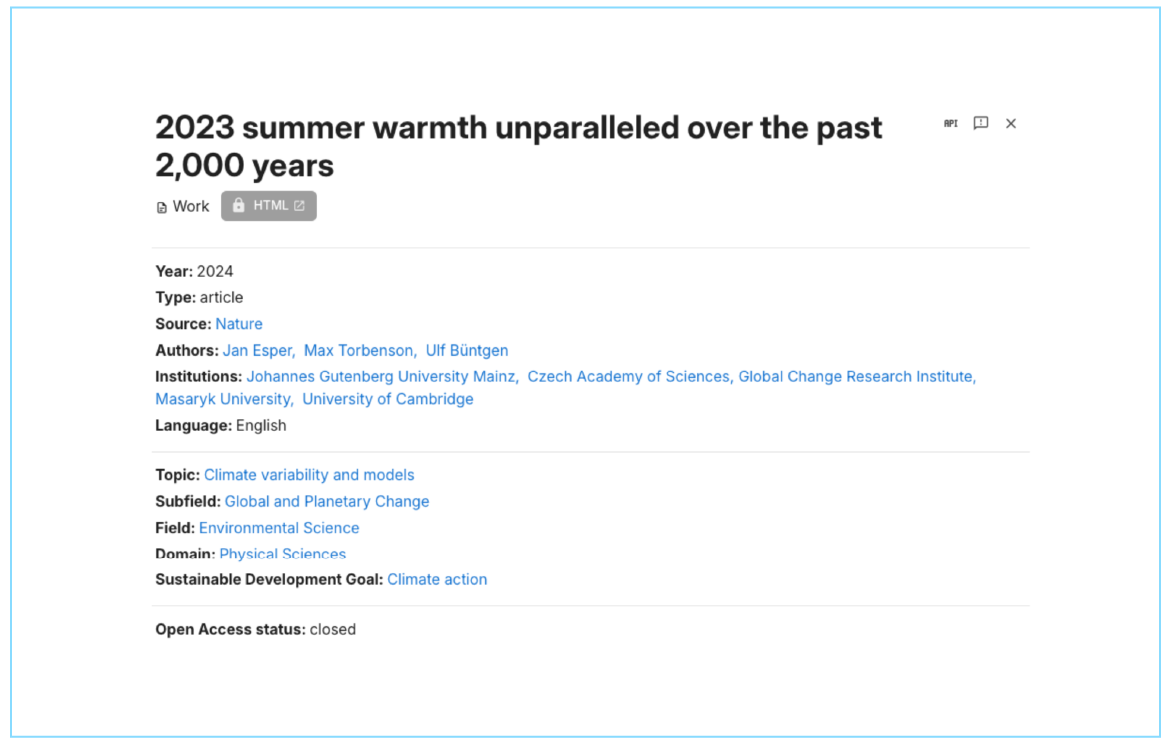
Carbon Brief downloaded all of the paper abstracts – the short summaries at the top of any study. This will facilitate future analysis, such as keyword searching or sentiment analysis.
Carbon Brief used OpenAlex to identify the second-order references and retrieve the metadata. Google Scholar was used to identify citations – the articles that cite the IPCC – and OpenAlex used to collect the relevant metadata.
These entries are all stored in an online repository, hosted on MongoDB. This is what Carbon Brief refers to as the “raw database”.
From here, all entries were checked to ensure that they are formatted correctly and have the required metadata, before being transferred over into a second repository constructed using Neo4j. This is a system specially designed to manage and visualise “highly connected data”, enabling Carbon Brief to carry out analysis of the citation data more easily.
This is the “main database”.
How can researchers access the database?
Carbon Brief has published an initial wave of preliminary analysis to demonstrate the scope of the Cosmos database.
In the coming months and years, Carbon Brief intends to undertake further rounds of analysis. The Cosmos database will now be updated and expanded at the end of each calendar year.
Carbon Brief has chosen deliberately not to make the database open source, due to the risk of its contents being scraped and used by AI bots.
However, there are countless possibilities for future avenues of research using the Cosmos database and Carbon Brief now invites researchers – academics, journalists, analysts, etc – to submit their own proposals for co-authored studies and projects.
Proposals should be sent to: cosmos AT carbonbrief DOT org
How to cite Project Cosmos:
Hickman, L. et al. Introducing Project Cosmos: Carbon Brief’s ‘universe’ of climate science (Carbon Brief, 2026) https://interactive.carbonbrief.org/cosmos/index.html